Patient trajectory analysis#
In this notebook, I’ll show you an example of sample representation analysis to infer COVID severity trajectory
First, let’s import some packages. You might be unfamiliar with ehrapy: a package from Theis lab. It is an extension of scanpy for electronic health record (EHR) analysis. Many methods fully overlap (e.g. scanpy.tl.pca -> ehrapy.tl.pca) but there are a bit more. Think of it as scanpy but with a bit more cool features and support for categorical data.
import patpy
import ehrapy as ep
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import scanpy as sc
Here, I use COMBAT dataset. It contains PBMC from 140 individuals with various COVID severity. You can find processed dataset, more information about it, and link to the publication on Kaggle.
adata = sc.read_h5ad("/Users/vladimir.shitov/Documents/programming/pat_rep_benchmark/data/combat/combat_processed.h5ad")
adata
AnnData object with n_obs × n_vars = 783677 × 3000
obs: 'Annotation_cluster_id', 'Annotation_cluster_name', 'Annotation_minor_subset', 'Annotation_major_subset', 'Annotation_cell_type', 'GEX_region', 'QC_ngenes', 'QC_total_UMI', 'QC_pct_mitochondrial', 'QC_scrub_doublet_scores', 'TCR_chain_composition', 'TCR_clone_ID', 'TCR_clone_count', 'TCR_clone_proportion', 'TCR_contains_unproductive', 'TCR_doublet', 'TCR_chain_TRA', 'TCR_v_gene_TRA', 'TCR_d_gene_TRA', 'TCR_j_gene_TRA', 'TCR_c_gene_TRA', 'TCR_productive_TRA', 'TCR_cdr3_TRA', 'TCR_umis_TRA', 'TCR_chain_TRA2', 'TCR_v_gene_TRA2', 'TCR_d_gene_TRA2', 'TCR_j_gene_TRA2', 'TCR_c_gene_TRA2', 'TCR_productive_TRA2', 'TCR_cdr3_TRA2', 'TCR_umis_TRA2', 'TCR_chain_TRB', 'TCR_v_gene_TRB', 'TCR_d_gene_TRB', 'TCR_j_gene_TRB', 'TCR_c_gene_TRB', 'TCR_productive_TRB', 'TCR_chain_TRB2', 'TCR_v_gene_TRB2', 'TCR_d_gene_TRB2', 'TCR_j_gene_TRB2', 'TCR_c_gene_TRB2', 'TCR_productive_TRB2', 'TCR_cdr3_TRB2', 'TCR_umis_TRB2', 'BCR_umis_HC', 'BCR_contig_qc_HC', 'BCR_functionality_HC', 'BCR_v_call_HC', 'BCR_v_score_HC', 'BCR_j_call_HC', 'BCR_j_score_HC', 'BCR_junction_aa_HC', 'BCR_total_mut_HC', 'BCR_s_mut_HC', 'BCR_r_mut_HC', 'BCR_c_gene_HC', 'BCR_clone_per_replicate_HC', 'BCR_clone_global_HC', 'BCR_clonal_abundance_HC', 'BCR_locus_LC', 'BCR_umis_LC', 'BCR_contig_qc_LC', 'BCR_functionality_LC', 'BCR_v_call_LC', 'BCR_v_score_LC', 'BCR_j_call_LC', 'BCR_j_score_LC', 'BCR_junction_aa_LC', 'BCR_total_mut_LC', 'BCR_s_mut_LC', 'BCR_r_mut_LC', 'BCR_c_gene_LC', 'COMBAT_ID', 'scRNASeq_sample_ID', 'COMBAT_participant_timepoint_ID', 'Source', 'Age', 'Sex', 'Race', 'BMI', 'Hospitalstay', 'Death28', 'Institute', 'PreExistingHeartDisease', 'PreExistingLungDisease', 'PreExistingKidneyDisease', 'PreExistingDiabetes', 'PreExistingHypertension', 'PreExistingImmunocompromised', 'Smoking', 'Symptomatic', 'Requiredvasoactive', 'Respiratorysupport', 'SARSCoV2PCR', 'Outcome', 'TimeSinceOnset', 'Ethnicity', 'Tissue', 'DiseaseClassification', 'Pool_ID', 'Channel_ID', 'ifn_1_score', '_scvi_batch', '_scvi_labels', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'total_counts_mt', 'log1p_total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'log1p_total_counts_ribo', 'pct_counts_ribo'
var: 'gene_ids', 'feature_types', 'highly_variable', 'highly_variable_rank', 'means', 'variances', 'variances_norm', 'highly_variable_nbatches', 'mt', 'ribo', 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts'
uns: 'Institute', 'ObjectCreateDate', 'Source_colors', 'Technology', 'X_scpoli', '_scvi_manager_uuid', '_scvi_uuid', 'genome_annotation_version', 'hvg', 'log1p', 'pca', 'scpoli_distances', 'scpoli_parameters', 'scpoli_samples'
obsm: 'X_pca', 'X_scANVI_batch', 'X_scANVI_sample', 'X_scVI_batch', 'X_scVI_sample', 'X_scpoli', 'X_umap', 'X_umap_source'
varm: 'PCs'
layers: 'X_raw_counts'
sample_key = "scRNASeq_sample_ID"
cell_type_key = "Annotation_major_subset"
The following file contains metadata for donors in COMBAT dataset. It is available on GitHub. We will work with it in ehrapy but note that this is just anndata you are used to in single-cell.
There is a bunch of patient representation methods precalculated. Each of them has distances matrix and UMAP in obsm, and donors clustering in obs. Think of patient representation as distances between patiens: if a distance is equal to 0, transcriptomics profiles of patients are identical. The bigger the number, the bigger the differences.
meta_adata = ep.io.read_h5ad("data/combat_meta_adata.h5ad")
meta_adata
AnnData object with n_obs × n_vars = 137 × 88
obs: 'Race', 'Institute', 'Tissue', 'DiseaseClassification', 'Pool_ID', 'Source', 'Ethnicity', 'longitudinal_oxygen_phase', 'sampled_at_max_severity', 'potential_exclude', 'low_cellnumber_exclude', 'oxygen_status_sample', 'diabetes', 'comp_total', 'comp_minimal', 'comp_minimal_hosp_covid', 'comp_minimal_plus_transitional', 'MJ_samples', 'random_vec_leiden', 'composition_leiden', 'pseudobulk_leiden', 'pseudobulk_scanvi_pool_leiden', 'pseudobulk_scanvi_leiden', 'pseudobulk_scpoli_leiden', 'pseudobulk_scvi_pool_leiden', 'pseudobulk_scvi_leiden', 'scpoli_leiden', 'mrvi_leiden', 'wasserstein_scanvi_pool_leiden', 'wasserstein_scanvi_leiden', 'wasserstein_scvi_pool_leiden', 'wasserstein_scvi_leiden', 'pilot_leiden', 'gloscope_combat_JS_GMM_25_leiden', 'gloscope_combat_KL_GMM_25_leiden', 'gloscope_combat_KL_KNN_25_leiden', 'WHO_ordinal_at_sample', 'Outcome'
uns: 'Institute_colors', 'Pool_ID_colors', 'Source_colors', 'composition_leiden_colors', 'composition_neighbors', 'encoded_non_numerical_columns', 'encoding_to_var', 'gloscope_combat_JS_GMM_25_leiden_colors', 'gloscope_combat_JS_GMM_25_neighbors', 'gloscope_combat_KL_GMM_25_leiden_colors', 'gloscope_combat_KL_GMM_25_neighbors', 'gloscope_combat_KL_KNN_25_leiden_colors', 'gloscope_combat_KL_KNN_25_neighbors', 'leiden', 'mrvi_leiden_colors', 'mrvi_neighbors', 'non_numerical_columns', 'numerical_columns', 'original_values_categoricals', 'pilot_leiden_colors', 'pilot_neighbors', 'pseudobulk_leiden_colors', 'pseudobulk_neighbors', 'pseudobulk_scanvi_leiden_colors', 'pseudobulk_scanvi_neighbors', 'pseudobulk_scanvi_pool_leiden_colors', 'pseudobulk_scanvi_pool_neighbors', 'pseudobulk_scpoli_leiden_colors', 'pseudobulk_scpoli_neighbors', 'pseudobulk_scvi_leiden_colors', 'pseudobulk_scvi_neighbors', 'pseudobulk_scvi_pool_leiden_colors', 'pseudobulk_scvi_pool_neighbors', 'random_vec_leiden_colors', 'random_vec_neighbors', 'scpoli_leiden_colors', 'scpoli_neighbors', 'var_to_encoding', 'wasserstein_scanvi_leiden_colors', 'wasserstein_scanvi_neighbors', 'wasserstein_scanvi_pool_leiden_colors', 'wasserstein_scanvi_pool_neighbors', 'wasserstein_scvi_leiden_colors', 'wasserstein_scvi_neighbors', 'wasserstein_scvi_pool_leiden_colors', 'wasserstein_scvi_pool_neighbors'
obsm: 'composition_UMAP', 'composition_distances', 'gloscope_combat_JS_GMM_25_UMAP', 'gloscope_combat_JS_GMM_25_distances', 'gloscope_combat_KL_GMM_25_UMAP', 'gloscope_combat_KL_GMM_25_distances', 'gloscope_combat_KL_KNN_25_UMAP', 'gloscope_combat_KL_KNN_25_distances', 'mrvi_UMAP', 'mrvi_distances', 'pilot_UMAP', 'pilot_distances', 'pseudobulk_UMAP', 'pseudobulk_distances', 'pseudobulk_scanvi_UMAP', 'pseudobulk_scanvi_distances', 'pseudobulk_scanvi_pool_UMAP', 'pseudobulk_scanvi_pool_distances', 'pseudobulk_scpoli_UMAP', 'pseudobulk_scpoli_distances', 'pseudobulk_scvi_UMAP', 'pseudobulk_scvi_distances', 'pseudobulk_scvi_pool_UMAP', 'pseudobulk_scvi_pool_distances', 'random_vec_UMAP', 'random_vec_distances', 'scpoli_UMAP', 'scpoli_distances', 'umap', 'wasserstein_scanvi_UMAP', 'wasserstein_scanvi_distances', 'wasserstein_scanvi_pool_UMAP', 'wasserstein_scanvi_pool_distances', 'wasserstein_scvi_UMAP', 'wasserstein_scvi_distances', 'wasserstein_scvi_pool_UMAP', 'wasserstein_scvi_pool_distances'
layers: 'original'
obsp: 'composition_neighbors_connectivities', 'composition_neighbors_distances', 'gloscope_combat_JS_GMM_25_neighbors_connectivities', 'gloscope_combat_JS_GMM_25_neighbors_distances', 'gloscope_combat_KL_GMM_25_neighbors_connectivities', 'gloscope_combat_KL_GMM_25_neighbors_distances', 'gloscope_combat_KL_KNN_25_neighbors_connectivities', 'gloscope_combat_KL_KNN_25_neighbors_distances', 'mrvi_neighbors_connectivities', 'mrvi_neighbors_distances', 'pilot_neighbors_connectivities', 'pilot_neighbors_distances', 'pseudobulk_neighbors_connectivities', 'pseudobulk_neighbors_distances', 'pseudobulk_scanvi_neighbors_connectivities', 'pseudobulk_scanvi_neighbors_distances', 'pseudobulk_scanvi_pool_neighbors_connectivities', 'pseudobulk_scanvi_pool_neighbors_distances', 'pseudobulk_scpoli_neighbors_connectivities', 'pseudobulk_scpoli_neighbors_distances', 'pseudobulk_scvi_neighbors_connectivities', 'pseudobulk_scvi_neighbors_distances', 'pseudobulk_scvi_pool_neighbors_connectivities', 'pseudobulk_scvi_pool_neighbors_distances', 'random_vec_neighbors_connectivities', 'random_vec_neighbors_distances', 'scpoli_neighbors_connectivities', 'scpoli_neighbors_distances', 'wasserstein_scanvi_neighbors_connectivities', 'wasserstein_scanvi_neighbors_distances', 'wasserstein_scanvi_pool_neighbors_connectivities', 'wasserstein_scanvi_pool_neighbors_distances', 'wasserstein_scvi_neighbors_connectivities', 'wasserstein_scvi_neighbors_distances', 'wasserstein_scvi_pool_neighbors_connectivities', 'wasserstein_scvi_pool_neighbors_distances'
Here, we’ll focus on the GloScope representation obtained on scPoli cell embeddings. Notably, this method doesn’t use any information about patients: neither their clinical status nor even cell type annotation of the data. However, as we’ll see, it provides extremely good patient representation.
representation = "gloscope_combat_KL_KNN_25"
# Set obsm key so that standart umap plotting uses this representation
meta_adata.obsm["umap"] = meta_adata.obsm[f"{representation}_UMAP"]
# Plot UMAP, just like in scanpy. Note that every dot is a donor here!
ep.pl.umap(meta_adata, color=[f"{representation}_leiden", "Source"])
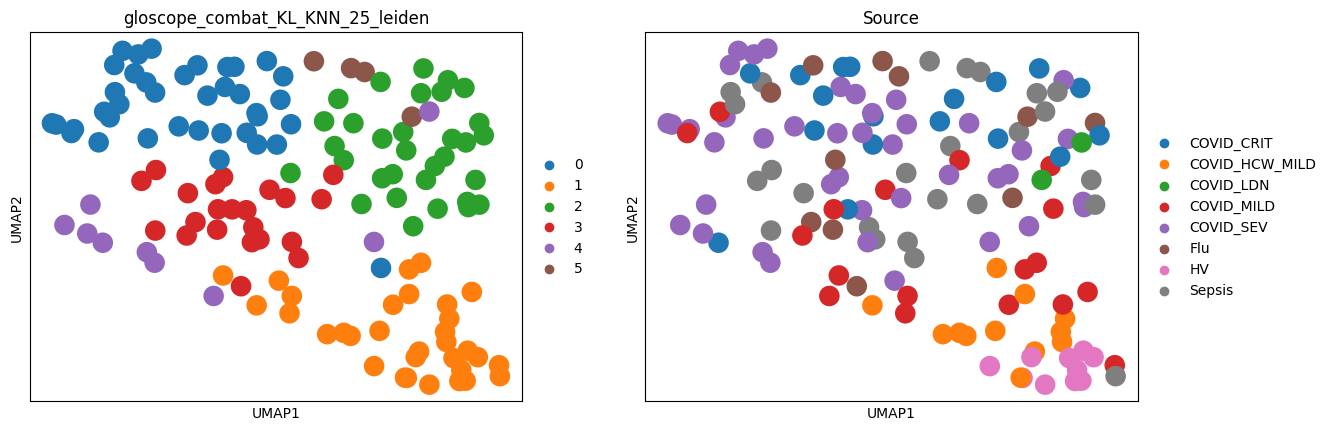
Let’s rename some of the columns for a better readability:
meta_adata.obs["Source"] = meta_adata.obs["Source"].map(
{
"HV": "Healthy",
"COVID_MILD": "Mild",
"COVID_SEV": "Severe",
"COVID_CRIT": "Critical",
"COVID_HCW_MILD": "Mild", # These are healthcare workers with mild disease
"COVID_LDN": "Critical",
"Sepsis": "Sepsis",
"Flu": "Flu",
}
)
source_palette = {
"Healthy": "#1f77b4", # HV
"Mild": "#ff9999", # COVID_MILD
"Severe": "#ff4c4c", # COVID_SEV
"Critical": sns.color_palette("Reds")[-1], # COVID_CRIT
# "Other": "darkgrey",
"Sepsis": "#8c564b", # Sepsis
"Flu": "#ff7f0e", # Flu
}
no_box = {
"axes.spines.top": False,
"axes.spines.right": False,
"axes.spines.left": False,
"axes.spines.bottom": False,
"xtick.bottom": False,
"xtick.labelbottom": False,
"ytick.left": False,
"ytick.labelleft": False,
}
plot_params = {"figure.figsize": (5, 5), "figure.dpi": 150, "axes.grid": False}
plot_params.update(no_box)
with plt.rc_context(plot_params):
sns.scatterplot(
x=meta_adata.obsm[f"{representation}_UMAP"][:, 0],
y=meta_adata.obsm[f"{representation}_UMAP"][:, 1],
hue=meta_adata.obs["Source"],
palette=source_palette,
hue_order=source_palette.keys(),
s=150,
)
plt.legend(loc=(1.05, 0.6), title="Condition")
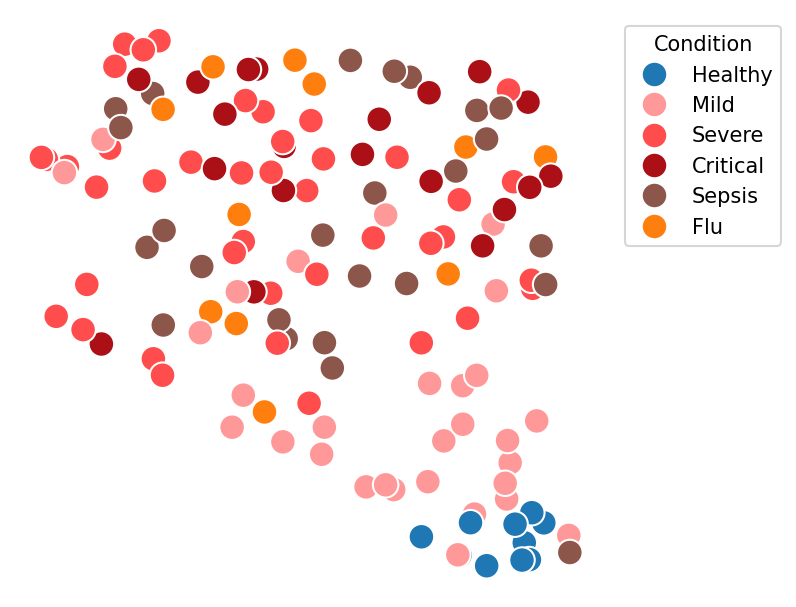
Note how all the healthy donors group together, and the severity gradient to the top. This is remarkable because sample representation methods knows nothing about donors condition and only evaluates how similar their transcriptomics profiles are. There are also some mild and even a septic patient grouping together with healthy. Are those errors of the method or misannotations?
With ehrapy, we can apply some single-cell methods to our data. For example, having a sample representation, we can discover trajectories in it via diffusion pseudotime. For this, we need to set the start of trajectory. Let’s take a look at the lowest patient on the UMAP:
control_donor_idx = meta_adata.obsm[f"{representation}_UMAP"][:, 1].argmin()
control_donor = meta_adata.obs_names[control_donor_idx]
meta_adata.obs.loc[control_donor, "Source"]
'Healthy'
Some variables are stored in meta_adata.X rather then in .obs. You can check which ones by running meta_adata.var_names
meta_adata[control_donor, ["Age", "Sex", "BMI", "Smoking"]].X
ArrayView([[74., 0., 5., 0.]], dtype=float32)
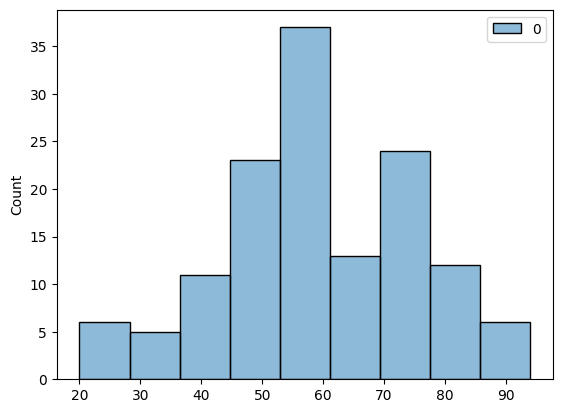
Ok, so we have a 74-years old non-smoking individual. Perhaps, somebody younger would be a better control but this should be a good start. Also, the dataset has a bit of bias for the older population:
sns.histplot(meta_adata[:, "Age"].X)
<Axes: ylabel='Count'>
Let’s set this individual as a root for pseudotime, and run the diffusion:
meta_adata.uns["iroot"] = np.flatnonzero(meta_adata.obs_names == control_donor)[0]
ep.tl.dpt(meta_adata, neighbors_key=f"{representation}_neighbors")
WARNING: Trying to run `tl.dpt` without prior call of `tl.diffmap`. Falling back to `tl.diffmap` with default parameters.
We now have a contunuous score from 0 (for the root we set) to 1 (for a most dissimilar sample), putting every donor on a continuous trajectory
with plt.rc_context(plot_params):
sns.scatterplot(
x=meta_adata.obsm[f"{representation}_UMAP"][:, 0],
y=meta_adata.obsm[f"{representation}_UMAP"][:, 1],
hue=meta_adata.obs["dpt_pseudotime"],
s=150,
palette="Reds",
)
plt.legend(loc=(1.05, 0.6), title="Diffusion pseudotime")
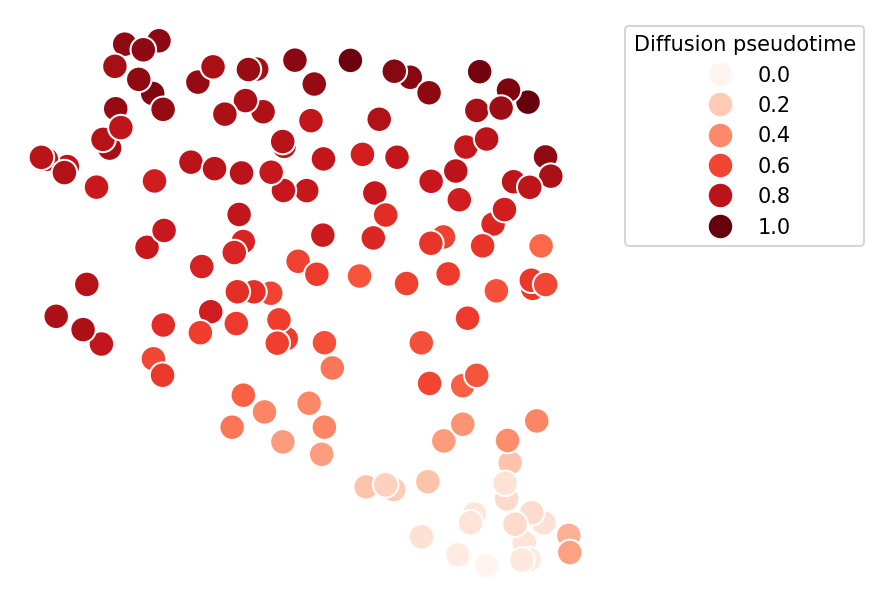
But is this score meaningful? Let’s take a look at how it corresponds to the severity:
sns.boxplot(
x=meta_adata.obs["dpt_pseudotime"],
y=meta_adata.obs["Source"],
palette=source_palette,
order=[key for key in source_palette.keys() if key in meta_adata.obs["Source"].unique()],
)
plt.xlabel("Diffusion pseudotime (severity score)")
plt.ylabel("")
Text(0, 0.5, '')
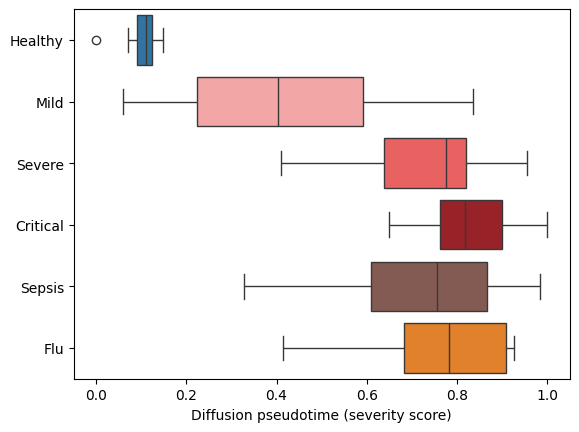
We see that higher severity patients have a higher pseudotime score! But instead of a coarse clinical resolution, we now have a continuous trajectory. We now can take a look at what correlates with this trajectory. It could be:
Cell type proportions
Gene expression
For the former, let’s calculate cell type composition for each patient. You can easily do it with patpy package:
cell_type_corrs = patpy.tl.correlate_composition(
meta_adata=meta_adata,
expression_adata=adata,
sample_key=sample_key,
cell_type_key=cell_type_key,
target="dpt_pseudotime",
)
cell_type_corrs
| correlation | p_value | p_value_adj | -log_p_value_adj | |
|---|---|---|---|---|
| PB | 0.451239 | 3.131071e-08 | 5.322821e-07 | 14.446092 |
| PLT | 0.435727 | 1.028075e-07 | 5.825759e-07 | 14.355806 |
| DC | -0.438586 | 8.293978e-08 | 5.825759e-07 | 14.355806 |
| cMono | 0.430760 | 1.485891e-07 | 6.315037e-07 | 14.275162 |
| MAIT | -0.422133 | 2.778327e-07 | 9.446311e-07 | 13.872471 |
| HSC | 0.339631 | 4.902797e-05 | 1.389126e-04 | 8.881666 |
| NK | -0.333424 | 6.850823e-05 | 1.663771e-04 | 8.701253 |
| iNKT | -0.298163 | 4.019908e-04 | 8.542304e-04 | 7.065310 |
| CD8 | -0.291742 | 5.421241e-04 | 1.024012e-03 | 6.884027 |
| DN | -0.238690 | 4.970933e-03 | 7.682351e-03 | 4.868830 |
| GDT | -0.240101 | 4.712976e-03 | 7.682351e-03 | 4.868830 |
| DP | -0.231360 | 6.524369e-03 | 9.242856e-03 | 4.683904 |
| ncMono | -0.220700 | 9.553095e-03 | 1.249251e-02 | 4.382626 |
| RET | 0.205614 | 1.593459e-02 | 1.934915e-02 | 3.945107 |
| CD4 | -0.193011 | 2.383841e-02 | 2.701686e-02 | 3.611294 |
| B | 0.172737 | 4.353834e-02 | 4.625949e-02 | 3.073489 |
| Mast | -0.051713 | 5.484133e-01 | 5.484133e-01 | 0.600726 |
Note that in the COMBAT paper, authors define the following hallmarks of COVID severity:
Increased level of plasmoblasts (PB), classical monocytes (cMono), platelets (PLT), hemapoetic stem cells (HSCs)
Decreased levels of dendritic cells (DC), NK cells, T
This is precicely what we see! Interestingly, But for MAIT, our results contradict the paper: they suggest that this cell type should be positively correlated with severity.
But are there particular cell states or gene progrmas that explain COVID? To find them, let’s take a look at the average gene expression within each cell type, and correlate it with our severity score
expression_dpt_correlation_df = patpy.tl.correlate_cell_type_expression(
meta_adata=meta_adata,
expression_adata=adata,
sample_key=sample_key,
cell_type_key=cell_type_key,
target="dpt_pseudotime",
layer="X",
min_sample_size=500,
)
1 samples removed: U00504-Ua005E-PBUa
expression_dpt_correlation_df
| cell_type | gene_name | correlation | p_value | n_observations | p_value_adj | -log_p_value_adj | |
|---|---|---|---|---|---|---|---|
| 9161 | cMono | S100A8 | 0.884355 | 1.671033e-46 | 137 | 8.079777e-42 | 94.619210 |
| 11813 | cMono | NKG7 | 0.876631 | 1.003818e-44 | 137 | 2.426831e-40 | 91.216818 |
| 11694 | cMono | MCEMP1 | 0.868571 | 5.428303e-43 | 137 | 8.748976e-39 | 87.631882 |
| 11946 | cMono | LGALS1 | 0.867283 | 1.002285e-42 | 137 | 1.211562e-38 | 87.306323 |
| 11277 | cMono | CYP19A1 | 0.866300 | 1.593919e-42 | 137 | 1.541384e-38 | 87.065553 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 49299 | Mast | CRLF2 | -0.074605 | 6.344566e-01 | 43 | 1.000000e+00 | -0.000000 |
| 49584 | Mast | LCN6 | -0.074605 | 6.344566e-01 | 43 | 1.000000e+00 | -0.000000 |
| 49651 | Mast | TCN1 | -0.074605 | 6.344566e-01 | 43 | 1.000000e+00 | -0.000000 |
| 49827 | Mast | GLRX3 | -0.075151 | 6.319715e-01 | 43 | 1.000000e+00 | -0.000000 |
| 49645 | Mast | PRG2 | -0.075699 | 6.294827e-01 | 43 | 1.000000e+00 | -0.000000 |
48352 rows × 7 columns
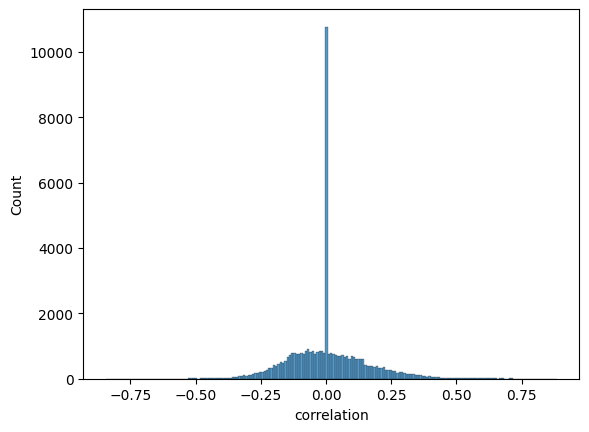
sns.histplot(expression_dpt_correlation_df["correlation"]);
sns.histplot(expression_dpt_correlation_df["p_value"]);
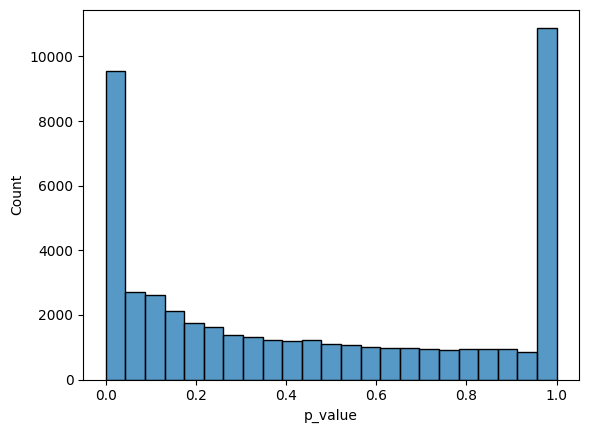
The p-values distribution above is not uniform, and has a peak around 0, which suggests that there are some genes with statistically significant correlation. Let’s take a look at top correlated genes:
expression_dpt_correlation_df.head(50)
| cell_type | gene_name | correlation | p_value | n_observations | p_value_adj | -log_p_value_adj | |
|---|---|---|---|---|---|---|---|
| 9161 | cMono | S100A8 | 0.884355 | 1.671033e-46 | 137 | 8.079777e-42 | 94.619210 |
| 11813 | cMono | NKG7 | 0.876631 | 1.003818e-44 | 137 | 2.426831e-40 | 91.216818 |
| 11694 | cMono | MCEMP1 | 0.868571 | 5.428303e-43 | 137 | 8.748976e-39 | 87.631882 |
| 11946 | cMono | LGALS1 | 0.867283 | 1.002285e-42 | 137 | 1.211562e-38 | 87.306323 |
| 11277 | cMono | CYP19A1 | 0.866300 | 1.593919e-42 | 137 | 1.541384e-38 | 87.065553 |
| 10655 | cMono | MS4A4A | 0.863694 | 5.352660e-42 | 137 | 4.313530e-38 | 86.036477 |
| 9159 | cMono | S100A9 | 0.848246 | 4.359564e-39 | 137 | 3.011338e-35 | 79.488094 |
| 10026 | cMono | HLA-DMB | -0.844671 | 1.849540e-38 | 137 | 1.117862e-34 | 78.176475 |
| 10528 | cMono | ALDH1A1 | -0.844298 | 2.146335e-38 | 137 | 1.153106e-34 | 78.145434 |
| 9160 | cMono | S100A12 | 0.816351 | 5.465913e-34 | 137 | 2.642878e-30 | 68.105684 |
| 10417 | cMono | CLU | 0.811288 | 2.856435e-33 | 137 | 1.255585e-29 | 66.547366 |
| 10894 | cMono | TROAP | 0.810760 | 3.383662e-33 | 137 | 1.363390e-29 | 66.464993 |
| 9011 | cMono | ENO1 | 0.809244 | 5.490735e-33 | 137 | 2.042215e-29 | 66.060932 |
| 11035 | cMono | RNASE2 | 0.804894 | 2.149305e-32 | 137 | 7.423085e-29 | 64.770373 |
| 10918 | cMono | METTL7B | 0.804443 | 2.471023e-32 | 137 | 7.965261e-29 | 64.699878 |
| 10679 | cMono | CFL1 | 0.801459 | 6.164316e-32 | 137 | 1.862856e-28 | 63.850272 |
| 10623 | cMono | LDHA | 0.793166 | 7.222266e-31 | 137 | 2.054182e-27 | 61.449920 |
| 10921 | cMono | MYL6B | 0.784690 | 7.972819e-30 | 137 | 2.141676e-26 | 59.105624 |
| 11347 | cMono | CIITA | -0.768981 | 5.193181e-28 | 137 | 1.321583e-24 | 54.983212 |
| 10599 | cMono | CTSD | 0.765873 | 1.141259e-27 | 137 | 2.759108e-24 | 54.247135 |
| 10030 | cMono | HLA-DPB1 | -0.764123 | 1.768498e-27 | 137 | 4.071925e-24 | 53.857926 |
| 7616 | ncMono | ADM | 0.762942 | 2.371437e-27 | 137 | 5.211987e-24 | 53.611081 |
| 10545 | cMono | SEC61B | 0.762414 | 2.701950e-27 | 137 | 5.602700e-24 | 53.538794 |
| 10665 | cMono | FTH1 | -0.762298 | 2.780956e-27 | 137 | 5.602700e-24 | 53.538794 |
| 10444 | cMono | GGH | 0.761924 | 3.049297e-27 | 137 | 5.897585e-24 | 53.487499 |
| 9758 | cMono | ANXA3 | 0.758692 | 6.721239e-27 | 137 | 1.249944e-23 | 52.736359 |
| 11034 | cMono | RNASE3 | 0.755460 | 1.463405e-26 | 137 | 2.620688e-23 | 51.996020 |
| 10179 | cMono | HSPB1 | 0.755162 | 1.571551e-26 | 137 | 2.713844e-23 | 51.961091 |
| 11441 | cMono | TXNDC17 | 0.752651 | 2.850176e-26 | 137 | 4.752128e-23 | 51.400865 |
| 10386 | cMono | HMGB3 | 0.751162 | 4.043102e-26 | 137 | 6.516403e-23 | 51.085135 |
| 9287 | cMono | CENPF | 0.750981 | 4.218092e-26 | 137 | 6.579135e-23 | 51.075554 |
| 10696 | cMono | FOLR2 | -0.750695 | 4.509140e-26 | 137 | 6.813311e-23 | 51.040579 |
| 9191 | cMono | CD1C | -0.750489 | 4.731778e-26 | 137 | 6.933059e-23 | 51.023156 |
| 11650 | cMono | SLPI | 0.747222 | 1.007990e-25 | 137 | 1.433480e-22 | 50.296767 |
| 10552 | cMono | TXN | 0.746588 | 1.165624e-25 | 137 | 1.610293e-22 | 50.180456 |
| 9174 | cMono | FDPS | 0.742649 | 2.849516e-25 | 137 | 3.827217e-22 | 49.314734 |
| 9355 | cMono | BOLA3 | 0.740722 | 4.387039e-25 | 137 | 5.733030e-22 | 48.910628 |
| 10021 | cMono | HLA-DQA1 | -0.737926 | 8.147764e-25 | 137 | 1.036739e-21 | 48.318207 |
| 14921 | CD4 | MIF | 0.737698 | 8.568028e-25 | 137 | 1.062260e-21 | 48.293888 |
| 10018 | cMono | HLA-DRA | -0.734641 | 1.669887e-24 | 137 | 2.018560e-21 | 47.651903 |
| 9866 | cMono | MEF2C | -0.734319 | 1.790537e-24 | 137 | 2.111611e-21 | 47.606836 |
| 10166 | cMono | SEC61G | 0.730622 | 3.959189e-24 | 137 | 4.557969e-21 | 46.837410 |
| 11566 | cMono | BIRC5 | 0.729768 | 4.747083e-24 | 137 | 5.337930e-21 | 46.679449 |
| 10848 | cMono | CLEC4A | -0.728686 | 5.969285e-24 | 137 | 6.559701e-21 | 46.473342 |
| 13623 | CD4 | LDHA | 0.725540 | 1.154193e-23 | 137 | 1.240167e-20 | 45.836456 |
| 9228 | cMono | F5 | 0.724369 | 1.471996e-23 | 137 | 1.547260e-20 | 45.615216 |
| 10916 | cMono | ZNF385A | -0.724229 | 1.515288e-23 | 137 | 1.558876e-20 | 45.607737 |
| 11573 | cMono | P4HB | 0.722814 | 2.028650e-23 | 137 | 2.043527e-20 | 45.337025 |
| 11667 | cMono | SLCO4A1 | 0.720362 | 3.350763e-23 | 137 | 3.306451e-20 | 44.855826 |
| 10826 | cMono | MKI67 | 0.719580 | 3.927259e-23 | 137 | 3.733561e-20 | 44.734339 |
This list is largely dominated by classical monocytes. Look at the top correlated gene! In the paper, authors write that S100A8 is a known biomarker, and its expression in cMonocytes correlates with severity. Other markers they mention (S100A9, S100A12, negative marker HLA-DRA) can also be found in the table. Thus, our severity score works
Let’s visualize the correlated genes in classical monocytes as they by far dominate in the table. Average expression per sample is now stored in meta_adata.obsm in keys {cell_type}_pseudobulk. This is controlled by the argument keep_pseudobulks_in_data in patpy.tl.correlate_cell_type_expression, set it to False if you want to save memory
cmono_expression_df = meta_adata.obsm["cMono_pseudobulk"]
cmono_expression_df
| SAMD11 | ISG15 | TNFRSF18 | TNFRSF4 | TMEM240 | PRDM16 | SMIM1 | ACOT7 | HES2 | TAS1R1 | ... | S100B | MT-CO1 | MT-CO2 | MT-CO3 | MT-ND6 | MT-CYB | AC136616.2 | AC141272.1 | AC233755.2 | AC233755.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| scRNASeq_sample_ID | |||||||||||||||||||||
| S00078-Ja003E-PBCa | 0.000000 | 0.666305 | 0.001183 | 0.001026 | 0.000000 | 0.0 | 0.007825 | 0.001336 | 0.000000 | 0.000000 | ... | 0.002201 | 4.252630 | 4.054601 | 3.459366 | 0.253607 | 2.783757 | 0.0 | 0.000000 | 0.008152 | 0.024226 |
| G05064-Ja005E-PBCa | 0.000000 | 0.329458 | 0.000000 | 0.001716 | 0.000000 | 0.0 | 0.009752 | 0.006973 | 0.000000 | 0.000000 | ... | 0.005361 | 3.937209 | 3.933448 | 3.238184 | 0.120764 | 2.759863 | 0.0 | 0.000000 | 0.008778 | 0.001008 |
| N00027-Ja001E-PBGa | 0.000000 | 0.161210 | 0.000000 | 0.001394 | 0.000000 | 0.0 | 0.015552 | 0.001609 | 0.000000 | 0.000000 | ... | 0.010047 | 4.248434 | 4.193965 | 3.502021 | 0.204099 | 2.744123 | 0.0 | 0.000000 | 0.012055 | 0.003364 |
| N00040-Ja001E-PBGa | 0.000215 | 0.186256 | 0.000875 | 0.000637 | 0.000000 | 0.0 | 0.002057 | 0.023947 | 0.000204 | 0.000218 | ... | 0.005497 | 4.030371 | 3.831872 | 3.575325 | 0.584262 | 2.572893 | 0.0 | 0.000219 | 0.005552 | 0.018434 |
| S00066-Ja001E-PBCa | 0.000000 | 0.702043 | 0.000779 | 0.000201 | 0.000000 | 0.0 | 0.008773 | 0.008580 | 0.000407 | 0.000000 | ... | 0.003274 | 4.106230 | 3.834374 | 3.595163 | 0.707436 | 2.959860 | 0.0 | 0.000255 | 0.012751 | 0.018012 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| G05112-Ja005E-PBCa | 0.000000 | 2.783315 | 0.000000 | 0.002990 | 0.000000 | 0.0 | 0.005321 | 0.004147 | 0.000000 | 0.000000 | ... | 0.001852 | 3.401807 | 3.298067 | 2.567472 | 0.232005 | 1.962488 | 0.0 | 0.000000 | 0.008089 | 0.004275 |
| S00042-Ja001E-PBCa | 0.000000 | 0.076010 | 0.000700 | 0.000000 | 0.000000 | 0.0 | 0.011200 | 0.007901 | 0.000000 | 0.000987 | ... | 0.003222 | 4.230716 | 4.037877 | 3.988372 | 0.513297 | 2.790164 | 0.0 | 0.000000 | 0.008693 | 0.024193 |
| S00067-Ja001E-PBCa | 0.000000 | 0.403914 | 0.000000 | 0.002425 | 0.000541 | 0.0 | 0.009077 | 0.005603 | 0.000926 | 0.000000 | ... | 0.030901 | 4.086512 | 3.805610 | 3.605104 | 0.434191 | 2.720078 | 0.0 | 0.000000 | 0.032481 | 0.014675 |
| N00006-Ja003E-PBGa | 0.000000 | 0.219691 | 0.000000 | 0.000739 | 0.000000 | 0.0 | 0.018713 | 0.000641 | 0.000000 | 0.000000 | ... | 0.001720 | 4.694515 | 4.340000 | 4.050896 | 0.706753 | 3.369446 | 0.0 | 0.000000 | 0.010999 | 0.023512 |
| S00113-Ja005E-PBCa | 0.000000 | 0.506833 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.007888 | 0.010469 | 0.000000 | 0.000000 | ... | 0.001530 | 4.045323 | 4.325161 | 4.005432 | 0.671465 | 3.210887 | 0.0 | 0.000000 | 0.018759 | 0.026449 |
137 rows × 3000 columns
top_genes = expression_dpt_correlation_df.sort_values(["p_value", "correlation"]).head(15)
pseudotime = meta_adata.obs["dpt_pseudotime"]
# Set up the plot
fig, axes = plt.subplots(3, 5, figsize=(15, 9))
fig.suptitle("Cell Type gene expression vs Pseudotime", fontsize=16)
# Flatten the axes array for easier iteration
axes_flat = axes.flatten()
# Plot scatterplots for each significant cell type
for i, (_, row) in enumerate(top_genes.iterrows()):
ax = axes_flat[i]
gene_expression = cmono_expression_df.loc[pseudotime.index, row["gene_name"]]
sns.scatterplot(x=pseudotime, y=gene_expression, ax=ax, alpha=0.6)
# Add regression line
sns.regplot(x=pseudotime, y=gene_expression, ax=ax, scatter=False, color="red")
# Set title with correlation value
correlation = row["correlation"]
ax.set_title(f"{row['gene_name']}\nr = {correlation:.2f}", fontsize=10)
# Set labels
ax.set_xlabel("Pseudotime", fontsize=8)
ax.set_ylabel("Expression", fontsize=8)
# Adjust tick label size
ax.tick_params(axis="both", which="major", labelsize=6)
# Remove any unused subplots
for j in range(i + 1, len(axes_flat)):
fig.delaxes(axes_flat[j])
plt.tight_layout()
plt.show()
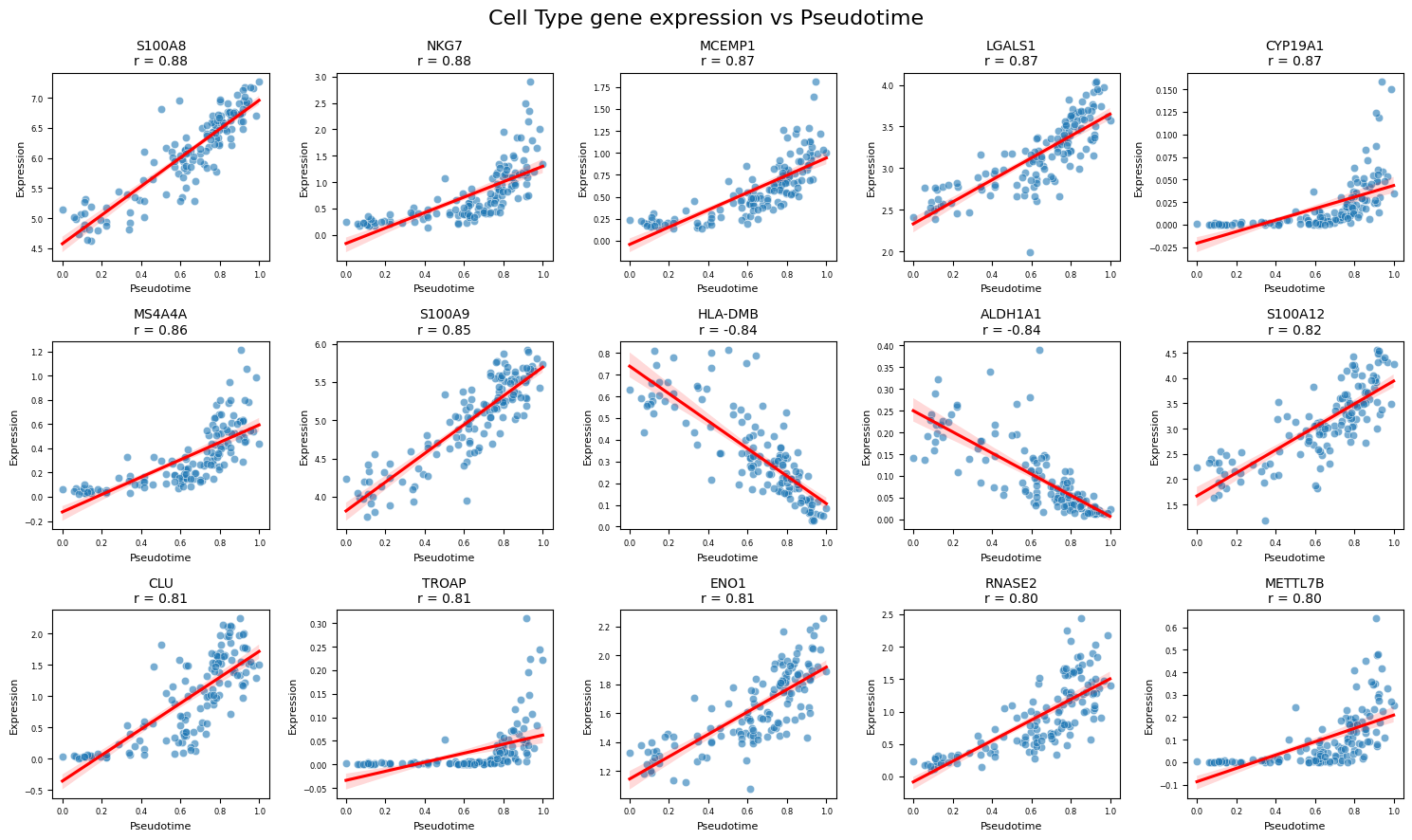
There are certainly non-linear dependencies but S100A8 is a great marker indeed. Let’s take a look how it alone explains the severity:
gene_expression = cmono_expression_df.loc[pseudotime.index, "S100A8"]
sns.boxplot(
x=gene_expression.loc[meta_adata.obs_names],
y=meta_adata.obs["Source"],
palette=source_palette,
order=[key for key in source_palette.keys() if key in meta_adata.obs["Source"].unique()],
)
plt.xlabel("Gene expression")
plt.ylabel("")
Text(0, 0.5, '')
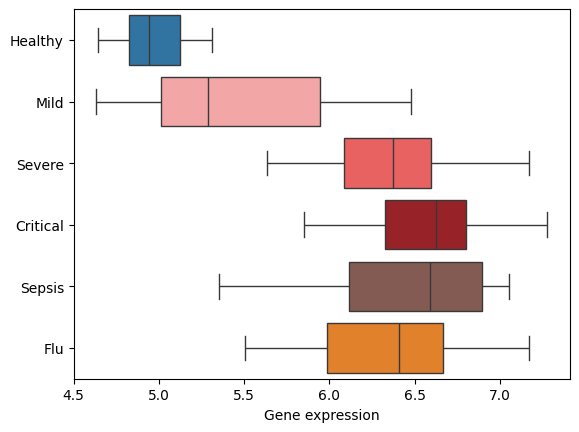
Well, our score works a bit better but this is definitely a good marker!
We can also visualize results on a volcano plot:
patpy.pl.correlation_volcano(expression_dpt_correlation_df, top_n=15);
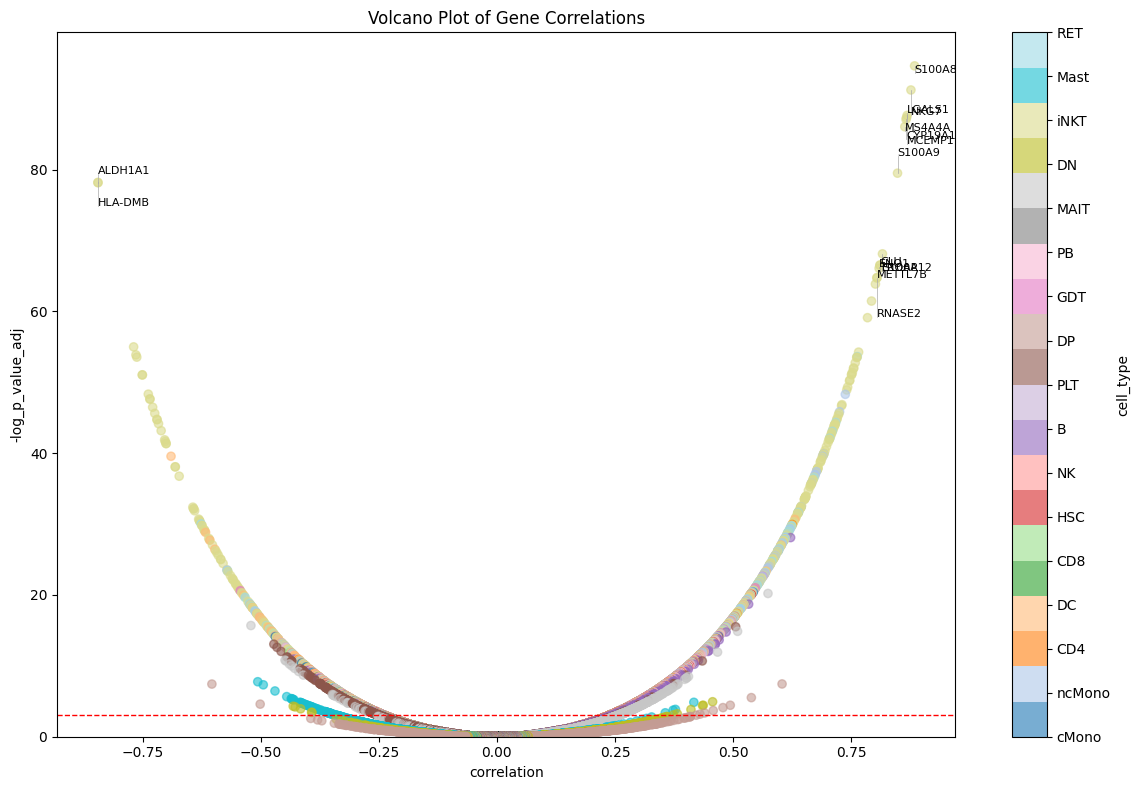
In summary, we have seen an example of sample-level analysis that allowed us to obtain a continuous severity score, find potential errors in the original clinical annotation, and easily rediscover known markers. Applying such methods to less explored areas might help you discover something new. With ehrapy and patpy it only requires running a few lines of code